
Top 12 Facebook Ads Library Web Scraping Tools in 2026: Ultimate Guide 🤖
In 2026 attempts to collect data from the Facebook Ads Library manually or through scripts to scrape Facebook ads library data increasingly end in blocks, CAPTCHAs and incomplete results. This is driven by Meta’s continuous strengthening of its antifraud algorithms, including AI-based bot detection, behavioral analysis and regular interface changes. ⚡️
That’s why scraping data from the Facebook Ads Library requires complex infrastructure: browser automation, JS rendering and JSON response parsing. However, even with this complex approach some data is still lost.
As a result, the market has shifted toward ready-made solutions like Facebook ads spy tools and full-scale API services. In this guide, we discover the best Facebook Ads Library web scraping tools and evaluate API vs Custom Web Scraper for Facebook. ⚙️
The State of Scraping Facebook Ads Library in 2026
Modern Meta Ads Library crawlers are more complex than simple HTML parsers. They must constantly adapt to a platform that actively resists third-party data collection. As a result, scrapers face several key challenges.
The first one is dynamic content. In the Ads Library data is loaded via JavaScript, so any Facebook ads library API scraper requires full JS rendering through a headless browser with Playwright or Puppeteer 🔗. This significantly increases the complexity of the scraping process.
The second issue is page structure. Scraping relies on selectors that indicate where elements like ad copy, CTA button or Landing page URL are located. They show the script exactly where to find the required information within the HTML structure. Selectors change regularly in the Ads Library. Meta may update the interface, restructure the layout or modify element classes. As a result, the parser stops seeing data in the usual places.
The third challenge comes from network-level restrictions. Meta applies rate limiting, monitors behavior patterns and blocks suspicious IPs. Without a proper bypass setup, access gets restricted very quickly. Even if it is in place, you still face additional checks like CAPTCHA solving ✅, use of anti-detect browsers and deep behavioral analysis.
As a result, traditional social media ad scraping software faces not just technical limitations, but systemic resistance from the platform itself. This has driven increased demand for Facebook Ads Library API services, where most of these challenges are already solved.
Build vs Buy: Why Creating Your Own Scraper is a Trap
At first glance, building your own scraper may seem like a more cost-effective solution. In reality, maintaining such a system quickly turns into a constant race against platform changes and rising costs 💰.
The Hidden Costs of Maintenance
The biggest mistake when building a custom parser is assuming it’s a one-time effort. In reality it requires constant maintenance due to ongoing changes on Meta’s side. Even well-written code quickly becomes outdated, forcing teams to spend time fixing and adapting it. As a result, development hours grow and time-to-market gets longer.
Infrastructure Nightmares
A single script is not enough for stable data collection. You need residential proxies, proxy rotation and a headless browser for JS rendering. On top of that, infrastructure maintenance, monitoring and protection against blocks are required. This increases server costs and makes scaling more complex.
Data Quality Issues
Even with a working system, data losses still occur due to CAPTCHAs and rate limits. This reduces data accuracy and leads to incomplete datasets. As a result, competitor analysis and the evaluation of winning ads become less reliable, lowering the overall value of the system.
Best Meta Ad Library Scrapers 2026: Detailed Review
In the niche of web scraping tools, two approaches coexist: traditional scrapers and next-generation API solutions. The first offers full control but requires complex infrastructure and ongoing maintenance, while the second removes the technical overhead and delivers ready-to-use data immediately. 🚀
1. Metapi.io — The Ultimate Solution for Ad Data Extraction 🏆
Metapi.io is a dedicated API-first scraping solution that provides direct API integration and access to structured data from Facebook Ads Library, including Page ID level data for precise tracking of advertisers and campaigns.
The core idea of the service is to remove all technical complexity related to data collection and let developers focus purely on working with structured JSON responses.
🔥 Key Metapi.io features include:
- Stable and predictable data delivery;
- Fast integration, with high-speed responses and no delays typical for browser-based scraping;
- Structured JSON format ready for analysis, including metrics such as ad spend estimation;
- Zero maintenance — no proxies, headless browsers, or anti-detection setup required;
- Affordable pricing for developers.
Metapi.io is built as a scalable backend for ad data extraction. It supports large-volume requests up to 100,000+ ads per query, provides access to over 2 years of historical data including removed ads and enables real-time monitoring via webhooks with sub-second latency.
Instead of spending resources on building and maintaining scrapers, teams can integrate a ready-to-use API and immediately start collecting ad intelligence, tracking competitors or powering analytics products.
Unlike traditional scraping solutions, Metapi.io focuses on delivering reliable, structured data at scale and not on the process of collecting it.
2. Apify (Facebook Ads Scraper)
Apify is a web scraping platform with a traditional approach: browser automation, proxies and scenario-based workflows for collecting data across multiple platforms beyond Meta.
The main advantage of Apify is its flexibility: you can customize the workflow for your specific needs, collect data in different formats and build custom pipelines to automate competitor ad research.
The downside is that the service depends on Facebook’s stability and requires full technical maintenance and resilience to interface changes. Compared to Metapi.io, which delivers ready-to-use data directly via API, Apify requires more hands-on control.
3. Bright Data
Bright Data is a web scraping platform that provides access through a proxy network, anti-bot bypass and ready-to-use scraping APIs.
Its main strength is full control and scalability: it allows big data collection using proxies, IP rotation and built-in blocking protection. This makes Bright Data a reliable Facebook ad data provider.
⚡️ In contrast to Metapi.io, Bright Data requires infrastructure setup and hands-on management of the entire scraping stack.
4. PhantomBuster
PhantomBuster is a no-code tool for automating tasks and simple scraping workflows on Meta and as well as other platforms, using ready-made scripts.
The main advantage is a high delivery rate: you can configure automated data collection without any development and get results in spreadsheets or JSON. This makes it convenient for marketers and small teams.
The downside is that it is limited in data depth and it quickly runs into the constraints of browser automation. Unlike Metapi.io, it does not provide stable access and requires constant adjustment of workflows.
5. AdSpy / PowerAdSpy
AdSpy and PowerAdSpy are classic Facebook ad creative research tools in 2026 that operate as closed databases.
Their main advantage is a ready-made structured data set and searchable ad library, which also works as a Facebook ads library search by keyword tool, allowing quick creative testing and hook extraction of ads without any technical setup.
The downside is the lack of a transparent Meta API for ad research. In comparison to Metapi.io, you don’t get real-time updates in Facebook Ads Library data as you work with a pre-collected dataset instead.
6. GetHookd / Swipekit
GetHookd and Swipekit are ad library monitoring tools for ad research, primarily designed for marketers.
Their main strength is usability: you can generate ad creatives (video/image), ad copy, CTA elements and ideas and discover different advertising approaches.
☝️ However, these are more inspiration tools than a full Meta Ad Library API service. Unlike Metapi.io, they do not provide structured data access and are not suitable for Ad library monitoring automation or large-scale analysis.
7. Octoparse
Octoparse is a classic no-code scraper for visual data extraction.
The main advantage is simplicity: you can set up scraping through a visual interface without coding and export Facebook ads to CSV or JSON.
The downside is weak handling of dynamic content and JS rendering, which makes stability heavily dependent on configuration. Compared to Metapi.io, it requires maintenance and tuning.
8. Oxylabs
Oxylabs is a web scraping platform offering ready-made APIs for social media ad scraping software.
Its main advantages are stability, proxy network and the ability to scale data collection without frequent blocks.
The downside is the complexity. Oxylabs remains a “build infrastructure” type solution rather than a ready-to-use API for fast data access.
9. WebScraper.io
WebScraper.io is a browser extension and cloud-based service for simple bulk download Facebook ads library workflows.
The main advantage is ease of entry: you can quickly set up scraping through a visual interface without coding.
The downside is limited scalability and strong dependency on page DOM structure. Compared to Metapi.io, it is better suited for one-off tasks rather than being a competitor ad intelligence software.
10. AdMake AI
AdMake AI is an AI-oriented tool for analyzing and generating advertising ideas.
The main advantage is the use of AI to identify patterns and analyze creatives without manual scraping or design work.
The downside is the lack of direct access to Ads Library data and reliance on internal models. Unlike Metapi.io, there is no full Meta API for ad research here — only interpretation of already collected data.
11. Scrapeless
Scrapeless is an API-based platform focused on reliable data extraction from protected websites, including social platforms and ad libraries.

Its main advantages include ready-to-use infrastructure, built-in handling of blocks, proxies, JS rendering and API-based delivery of structured data.
The downside is that it requires pipeline setup and API management. Unlike Metapi.io, where data is delivered as a ready-to-use product, Scrapeless still involves infrastructure handling on the user side.
12. Zyte
Zyte is a web scraping platform focused on infrastructure and handling complex websites.

Its main advantages are stability, scalability and advanced JS rendering for difficult scraping scenarios.
The downside is high setup complexity and the need for technical expertise. Unlike Metapi.io, Zyte requires technical knowledge rather than just simple API integration.
How to Choose the Right Tool for Your Business
🤔 Choosing web scraping tools in 2026 primarily comes down to balancing cost, functionality and complexity. On one side, there are flexible solutions with full scraping infrastructure; on the other, API services that remove the technical overhead and provide ready-to-use data.
If a business has a development team and resources for ongoing maintenance, more complex tools for custom data collection can be considered. However, if the goal is fast access to stable data without relying on proxies, parsers and infrastructure, the API approach becomes the more rational option.
Legal and Ethical Considerations of Scraping Meta Data
‼️ Collection of data from public sources within Meta’s ecosystem always exists in a gray area somewhere between technical feasibility and ethical scraping. Formally, data from the Ads Library is considered publicly available information. However, the methods of automated collection may still be governed by the platform’s Terms of Service (ToS).
A notable example is the legal dispute between Meta and Bright Data in 2024-2025. It addressed the boundaries of permissible automated access to publicly available data and the interpretation of platform terms. During the proceedings, the U.S. court ruled in favor of Bright Data on Meta’s key claims, after which Meta withdrew part of its allegations and the case was effectively closed without imposing restrictions on the defendant.
The market received an important signal: working with public data is not free of legal risk, but the outcome depends on the method of data collection and the legal interpretation of the parties’ actions. This has accelerated the shift toward API-based solutions that provide direct data access with lower legal uncertainty.
Step-by-Step: How to Integrate Metapi.io for Seamless Research
Integration with Metapi.io is designed to be as simple as possible and does not require any infrastructure such as proxies or browser automation. There are three steps here.
- Step 1: API key creation. This key is created in one click on the dashboard.

- Step 2: Request. Send a request to the system with the required parameters, such as keywords, pages or creatives and start run.
- Step 3: Get a response. A structured JSON file is returned with data ready for analysis and integration into internal systems.
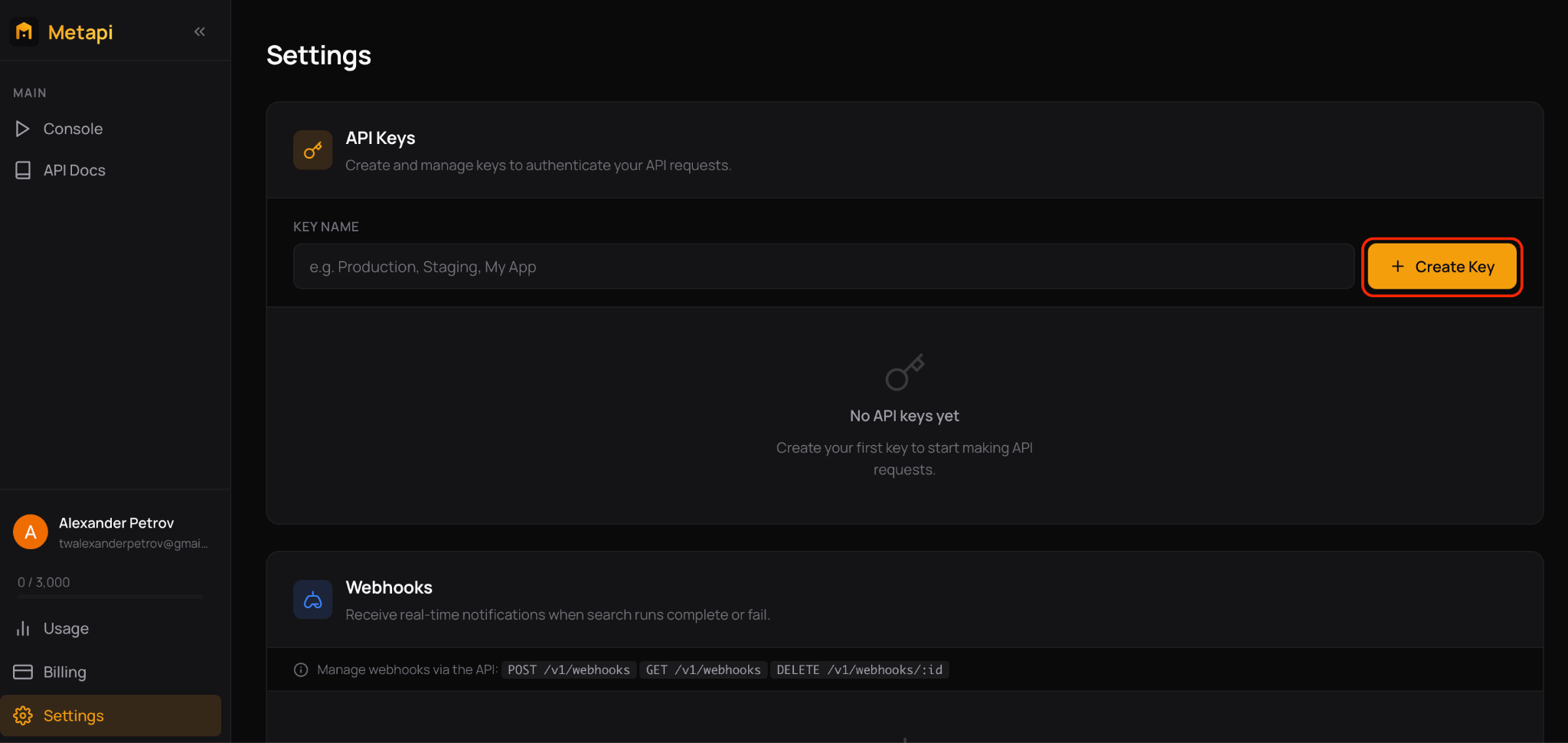
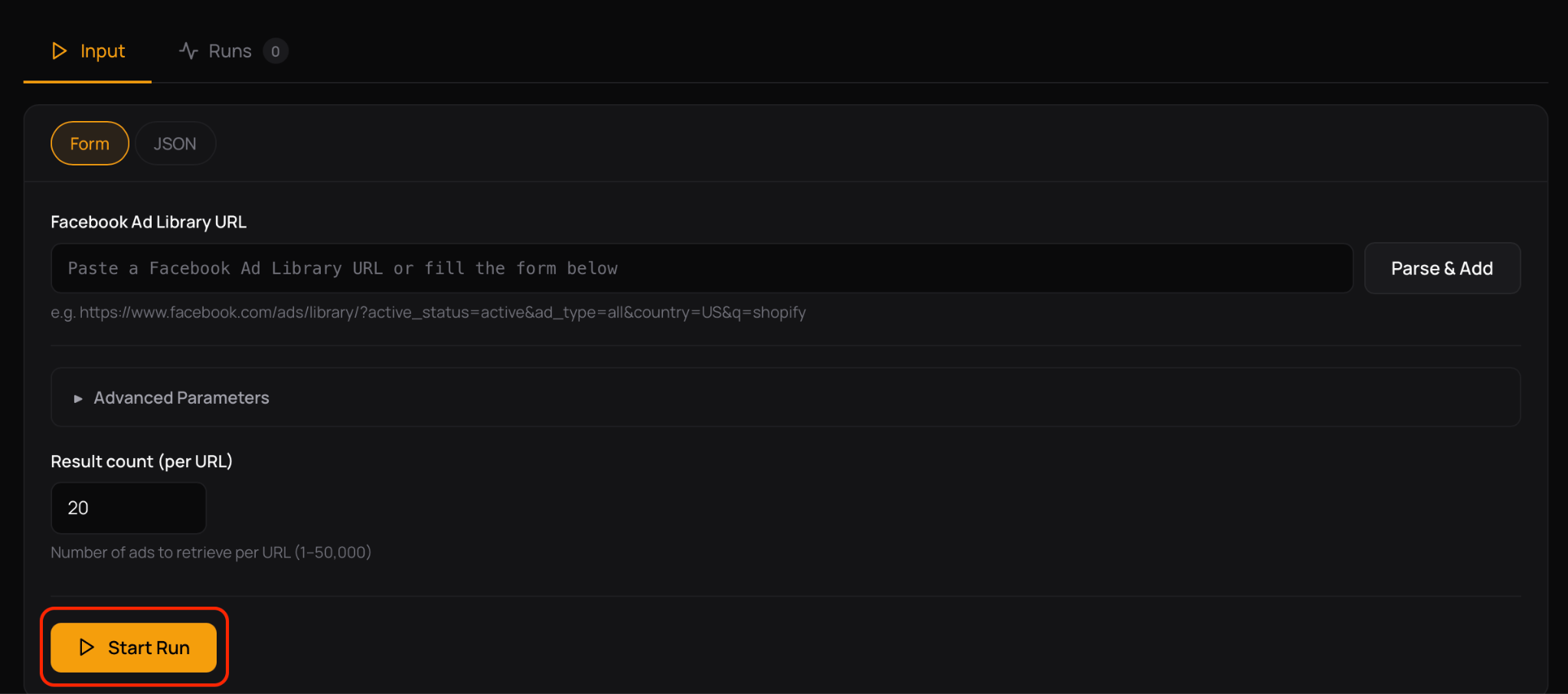
🤝 This allows teams to focus on ad research, rather than on how to extract data from Facebook Ads Library.
Conclusion
In 2026 time becomes a more valuable resource than attempts to bypass Meta’s restrictions and algorithms on your own. That is why Metapi.io is the choice of professionals working with Facebook Ads Library data, allowing them to focus on analysis rather than the technical implementation of data collection. 🗂️
FAQ
🔷 Why is my custom Facebook scraper not working anymore?
Because Meta regularly updates the structure of the Ads Library, changes page markup and modifies how data is loaded. As a result, custom scripts and Facebook Ads Library scraping tools often fail to correctly locate the required elements.
🔷 Is it legal to scrape the Facebook Ads Library in 2026?
In most cases, analyzing publicly available data does not violate copyright law. However, Meta’s platform terms of service may impose restrictions on automated data collection.
🔷 Can I scrape images and videos from the Ad Library?
Yes, using solutions that support media data handling, it is possible to extract creatives, including images and videos from ad campaigns.
🔷 Do I need coding skills to use these tools?
It depends on the approach: no-code tools allow usage without development, while API solutions require basic technical integration but offer greater flexibility and stability.
🔷 How to avoid being blocked by Meta while scraping?
Common methods include residential proxies, request rate distribution and simulating human-like behavior to reduce the risk of blocks.
🔷 What is the advantage of using Metapi.io over browser extensions?
The main advantages are stable API-based data access, no dependency on browsers or extensions and scalability without infrastructure limitations.
🔷 Is it cheaper to use an API than to buy proxies?
In most cases, yes, because an API reduces not only proxy and server costs but also development time and infrastructure maintenance.
🔷 Does Metapi.io support video ad extraction?
Yes, Metapi.io provides access to ad creatives, including video and other media formats.
🔷 How fast can I start getting data with an API?
Almost immediately after access is granted: simply sign up, obtain an API key, and start sending requests.







